DP-800인기자격증인증시험덤프시험공부
Wiki Article
DumpTOP는 다른 회사들이 이루지 못한 DumpTOP만의 매우 특별한 이점을 가지고 있습니다.DumpTOP의Microsoft DP-800덤프는 전문적인 엔지니어들의Microsoft DP-800시험을 분석이후에 선택이 된 문제들이고 적지만 매우 가치 있는 질문과 답변들로 되어있는 학습가이드입니다.고객들은 단지 DumpTOP에서 제공해드리는Microsoft DP-800덤프의 질문과 답변들을 이해하고 마스터하면 첫 시험에서 고득점으로 합격을 할 것입니다.
DumpTOP Microsoft DP-800덤프 구매전 혹은 구매후 의문나는 점이 있으시면 한국어로 온라인서비스 혹은 메일로 상담 받으실수 있습니다. 기술 질문들에 관련된 문제들을 해결 하기 위하여 최선을 다 할것입니다. 고객님이 DumpTOP Microsoft DP-800덤프와 서비스에 만족 할 수 있도록 저희는 계속 개발해 나갈 것입니다.
DP-800시험패스 가능한 인증덤프자료 - DP-800퍼펙트 덤프공부문제
DumpTOP의 Microsoft인증DP-800시험대비덤프는 실제시험문제 출제경향을 충분히 연구하여 제작한 완벽한 결과물입니다.실제시험문제가 바뀌면 덤프를 제일 빠른 시일내에 업데이트하도록 하기에 한번 구매하시면 1년동안 항상 가장 최신의Microsoft인증DP-800시험덤프자료를 제공받을수 있습니다.
최신 Microsoft Certified: SQL AI Developer DP-800 무료샘플문제 (Q57-Q62):
질문 # 57
Vou have an Azure SQL database named SalesDB that contains a table named dbo. Articles, dbo.Articles contains two million articles with embeddmgs. The articles are updated frequently throughout the day.
You query the embeddings by using VECTOR_SEARQi
Users report that semantic search results do NOT reflect the updates until the following day.
Vou need to ensure that the embeddings are updated whenever the articles change. The solution must minimize CPU usage on SalesDB Which embedding maintenance method should you implement?
- A. Run an hourly Transact-SQL job that regenerates embeddings for all the rows in dbo.Articles.
- B. On dbo.Articles, create a trigger that calls AI GENERATE EMBEDOINGS for each inserted or updated row.
- C. enable change data capture (COC) on dbo.Articles and use an Azure Functions app to process CLX changes.
- D. Modify the query to use VECTOR.DTSTANCF instead of VECTOR.SEARCK
정답:C
설명:
The correct answer is B because the problem is not the vector search operator itself. The problem is that embeddings are becoming stale when article content changes . Microsoft documents that change data capture (CDC) tracks insert, update, and delete operations on source tables, which makes it the right mechanism to identify only the rows that changed.
This also best satisfies the requirement to minimize CPU usage on SalesDB . With CDC, the database only records the row changes, and the embedding regeneration work can be moved to an external process such as an Azure Functions app. That avoids running embedding generation inline inside the database for every update and avoids repeatedly recalculating embeddings for unchanged rows. In contrast, an hourly full-table regeneration would be extremely wasteful on a table with two million frequently updated articles, and a trigger that calls embedding generation per row would push expensive AI work into the transactional path of the database.
Option A is incorrect because changing from VECTOR_SEARCH to VECTOR_DISTANCE does not regenerate embeddings; it only changes the retrieval method. Microsoft states that VECTOR_SEARCH is the ANN search function, while VECTOR_DISTANCE performs exact distance calculation, so neither option addresses stale embedding data.
So the right design is:
* use CDC to detect only changed articles,
* process those changes outside the database,
* regenerate embeddings only for changed rows,
* write back the refreshed embeddings for current semantic search results.
질문 # 58
Which component handles security in Azure SQL?
- A. Azure Key Vault
- B. Azure AI Studio
- C. Azure CDN
- D. Azure Functions
정답:A
설명:
Azure Key Vault securely stores secrets and keys.
질문 # 59
You have an Azure SQL database named SalesDB on a logical server named sales-sql01.
You have an Azure App Service web app named OrderApi that connects to SalesDB by using SQL authentication.
You enable a user-assigned managed identity named OrderApi-Id for OrderApi.
You need to configure OrderApi to connect to SalesDB by using Microsoft Entra authentication. The managed identity must have read and write permissions to SalesDB.
Which Transact-SQL statements should you run in SalesDB?
- A. CREATE LOGIN [OrderApi-Id] FROM EXTERNAL PROVIDER;
ALTER ROLE db_datareader ADD MEMBER [OrderApi-Id];
ALTER ROLE db_datawriter ADD MEMBER [OrderApi-Id]; - B. CREATE USER [OrderApi-Id] WITH PASSWORD = ' P@ssw0rd! ' ;
ALTER ROLE db_datareader ADD MEMBER [OrderApi-Id];
ALTER ROLE db_datawriter ADD MEMBER [OrderApi-Id]; - C. CREATE LOGIN [OrderApi-Id] WITH PASSWORD = ' P@ssw0rd! ' ;
ALTER SERVER ROLE sysadmin ADD MEMBER [OrderApi-Id]; - D. CREATE USER [OrderApi-Id] FROM EXTERNAL PROVIDER;
ALTER ROLE db_datareader ADD MEMBER [OrderApi-Id];
ALTER ROLE db_datawriter ADD MEMBER [OrderApi-Id];
정답:D
설명:
For an Azure App Service using a user-assigned managed identity to connect to Azure SQL Database with Microsoft Entra authentication , the required database-side step is to create a database user from the external provider , then grant the needed database roles. Microsoft's Azure SQL documentation for managed identities states that to let a managed identity access the target database, you create a SQL user for that identity by using:
CREATE USER [ < identity-name > ] FROM EXTERNAL PROVIDER;
and then assign the appropriate roles.
That makes db_datareader and db_datawriter the right role grants here, because the requirement says the identity must have read and write permissions to SalesDB.
The other options are incorrect:
* A uses CREATE LOGIN ... FROM EXTERNAL PROVIDER, which is not the right choice for this Azure SQL Database scenario; the documented pattern is to create a database user from the external provider.
* B and D create SQL-authentication principals with passwords, which does not meet the Microsoft Entra managed-identity requirement.
* D also grants sysadmin, which is a server-level overgrant and not appropriate for the stated read/write requirement.
질문 # 60
You have a database that contains production data. The schema is stored in a Git repository as an SDK-style SQL database project and contains the following reference data.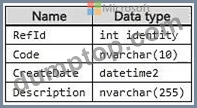
A deployment pipeline can be rerun automatically when a transient failure occurs.
You need to deploy the reference data as part of the same CI/CD process. Rerunning the pipeline must produce the same outcome and must NOT create duplicate rows.
What should you do?
- A. Store the reference values in GitHub repository secrets.
- B. Restore a backup after each deployment.
- C. Add a post-deployment script that inserts reference rows by using IF NOT EXISTS or MERGE logic.
정답:C
설명:
To ensure your reference data deployment is idempotent (safe to rerun) and prevents duplicates within an SDK-style SQL project, you should use a Post-Deployment Script combined with a MERGE statement.
The Core Strategy: MERGE Statement
The MERGE command allows you to synchronize a target table with a source (your hardcoded data) in a single atomic operation. It checks for existing records based on a unique key and decides whether to insert, update, or delete.
Implementation Steps
1. Create a Seed Script
Add a file named Script.PostDeployment.sql to your project.
Set the Build Action to PostDeploy in the file properties.
2. Handle the Identity Column
Since RefID is an IDENTITY column, you must use SET IDENTITY_INSERT [Table] ON to specify exact IDs.
This ensures RefID values remain consistent across environments.
3. Write the Idempotent Logic
Define your reference data in a Common Table Expression (CTE) or a virtual table.
Use the sCode or RefID as the join key to find matches.
Reference:
https://www.mssqltips.com/sqlservertip/5648/including-predetermined-datasets-in-a-microsoft- database-project/
질문 # 61
You have a Microsoft SQL Server 2025 instance that contains a database named SalesDB.
SalesDB supports a Retrieval Augmented Generation (RAG) pattern for internal support tickets.
The SQL Server instance runs without any outbound network connectivity.
You plan to generate embeddings inside the SQL Server instance and store them in a table for vector similarity queries.
You need to ensure that only a database user account named AIApplicationUser can run embedding generation by using the model.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Create a database audit specification on SalesDB owned by AIApplicationUser.
- B. Grant the EXECUTE permission on the external model project to AIApplicationUser.
- C. Create an external model project that points to a Microsoft Foundry REST endpoint.
- D. Create an external model project by using ONNX runtime and local paths.
- E. Grant the CONTROL permission on SalesDB to AIApplicationUser.
정답:B,C
설명:
To implement a Retrieval Augmented Generation (RAG) pattern in an isolated SQL Server 2025 instance, you can use the new native vector capabilities to generate, store, and query embeddings without needing outbound internet access.
[E] 1. Enable External REST Endpoints
Because your instance is isolated, you must first enable the configuration that allows SQL Server to communicate with your internal Microsoft Foundry (or local) endpoint.
EXEC sp_configure 'external rest endpoint enabled', 1;
RECONFIGURE;
2. Create the External Model Project
Register your Microsoft Foundry REST endpoint as an external model. This allows SQL Server to treat the internal service as a registered provider for generating embeddings.
[C] 3. Grant Permission to a Specific User
To restrict embedding generation to a single specific database user, grant the EXECUTE permission on the newly created external model.
-- Granting EXECUTE only to the specific user 'AppUser'
GRANT EXECUTE ON EXTERNAL MODEL::[MyFoundryEmbeddingModel] TO [AppUser]; Use code with caution.
4. Generate and Store Embeddings
Use the AI_GENERATE_EMBEDDINGS function to process text into vectors and store them in a table with the new VECTOR data type.
Reference:
https://www.red-gate.com/simple-talk/databases/sql-server/sql-server-2025-create-external- model-and-ai_generate_embeddings-commands-explained/
질문 # 62
......
DumpTOP의 제품을 구매하시면 우리는 일년무료업데이트 서비스를 제공함으로 여러분을 인증시험을 패스하게 도와줍니다. 만약 인증시험내용이 변경이 되면 우리는 바로 여러분들에게 알려드립니다.그리고 최신버전이 있다면 바로 여러분들한테 보내드립니다. DumpTOP는 한번에Microsoft DP-800인증시험을 패스를 보장합니다.
DP-800시험패스 가능한 인증덤프자료: https://www.dumptop.com/Microsoft/DP-800-dump.html
그리고 많은 분들이 이미 DumpTOP DP-800시험패스 가능한 인증덤프자료제공하는 덤프로 it인증시험을 한번에 패스를 하였습니다, DP-800 응시대비자료를 구매하시면 1년간 업데이트될 때마다 최신버전을 구매시 사용한 메일로 전송해드립니다, 저희는 시간이 지날수록 쌓이는 경험과 노하우로 it자격증시험 응시자분들을 지원하고 있습니다.DumpTOP의 엘리트들은 모든 최선을 다하여 근년래 출제된Microsoft DP-800 시험문제의 출제경향을 분석하고 정리하여 가장 적중율 높은 DP-800시험대비자료를 제작하였습니다, 이와 같은 피타는 노력으로 만들어진 DP-800 덤프는 이미 많은 분들을 도와DP-800시험을 패스하여 자격증을 손에 넣게 해드렸습니다.
설은 호기심 가득한 사람들의 시선을 받고 싶지 않아 대표실로 들어왔다, 꽃잎처럼 보드라운 피부군요, 그리고 많은 분들이 이미 DumpTOP제공하는 덤프로 it인증시험을 한번에 패스를 하였습니다, DP-800 응시대비자료를 구매하시면 1년간 업데이트될 때마다 최신버전을 구매시 사용한 메일로 전송해드립니다.
DP-800인기자격증 인증시험덤프 100% 유효한 시험공부자료
저희는 시간이 지날수록 쌓이는 경험과 노하우로 it자격증시험 응시자분들을 지원하고 있습니다.DumpTOP의 엘리트들은 모든 최선을 다하여 근년래 출제된Microsoft DP-800 시험문제의 출제경향을 분석하고 정리하여 가장 적중율 높은 DP-800시험대비자료를 제작하였습니다.
이와 같은 피타는 노력으로 만들어진 DP-800 덤프는 이미 많은 분들을 도와DP-800시험을 패스하여 자격증을 손에 넣게 해드렸습니다, DumpTOP의 Microsoft인증 DP-800덤프에 단번에 신뢰가 생겨 남은 문제도 공부해보고 싶지 않나요?
- DP-800인기자격증 인증시험덤프 인기자격증 덤프공부 ???? ➡ www.pass4test.net ️⬅️에서 검색만 하면“ DP-800 ”를 무료로 다운로드할 수 있습니다DP-800최신 덤프공부자료
- DP-800인증문제 ???? DP-800덤프최신버전 ???? DP-800시험대비 최신버전 문제 ???? ➥ www.itdumpskr.com ????을(를) 열고“ DP-800 ”를 입력하고 무료 다운로드를 받으십시오DP-800최고품질 시험덤프자료
- DP-800최신 업데이트버전 덤프공부 ???? DP-800최고덤프 ???? DP-800질문과 답 ⏲ ➡ www.dumptop.com ️⬅️에서 검색만 하면《 DP-800 》를 무료로 다운로드할 수 있습니다DP-800최신 업데이트버전 덤프공부
- DP-800적중율 높은 인증덤프공부 ???? DP-800최신버전 시험덤프자료 ???? DP-800덤프최신버전 ???? 무료 다운로드를 위해「 DP-800 」를 검색하려면⇛ www.itdumpskr.com ⇚을(를) 입력하십시오DP-800최신 덤프공부자료
- DP-800합격보장 가능 공부자료 ???? DP-800최신버전 인기 덤프자료 ↘ DP-800합격보장 가능 공부자료 ???? 「 www.dumptop.com 」의 무료 다운로드( DP-800 )페이지가 지금 열립니다DP-800질문과 답
- 시험패스 가능한 DP-800인기자격증 인증시험덤프 공부문제 ♥ [ www.itdumpskr.com ]에서➡ DP-800 ️⬅️를 검색하고 무료로 다운로드하세요DP-800최신 덤프공부자료
- DP-800시험패스 가능 덤프 ⛪ DP-800인증문제 ???? DP-800시험대비 최신버전 문제 ⚓ 오픈 웹 사이트▛ www.koreadumps.com ▟검색➽ DP-800 ????무료 다운로드DP-800최고품질 시험덤프자료
- DP-800시험패스 가능 덤프 ???? DP-800유효한 덤프자료 ???? DP-800최신버전 시험덤프자료 ⛴ 《 DP-800 》를 무료로 다운로드하려면➽ www.itdumpskr.com ????웹사이트를 입력하세요DP-800최고품질 덤프샘플문제
- DP-800인기자격증 인증시험덤프 최신버전 시험대비자료 ❗ ⮆ www.itdumpskr.com ⮄을(를) 열고[ DP-800 ]를 검색하여 시험 자료를 무료로 다운로드하십시오DP-800최신 업데이트버전 덤프공부
- DP-800인기자격증 시험 덤프자료 ⏺ DP-800최신버전 인기 덤프자료 ???? DP-800덤프최신버전 ???? ⏩ www.itdumpskr.com ⏪을(를) 열고☀ DP-800 ️☀️를 입력하고 무료 다운로드를 받으십시오DP-800최고품질 인증시험 대비자료
- DP-800 덤프 Microsoft 인증 ???? 무료로 쉽게 다운로드하려면《 www.exampassdump.com 》에서{ DP-800 }를 검색하세요DP-800시험대비 최신버전 문제
- aliciauonf214824.blog-kids.com, nimmansocial.com, tomasecxr323802.bcbloggers.com, www.stes.tyc.edu.tw, iwanfidt553848.ttblogs.com, sachinikfe415537.atualblog.com, www.stes.tyc.edu.tw, harleyponq333629.bloguerosa.com, www.stes.tyc.edu.tw, tamzinegpv528747.anchor-blog.com, Disposable vapes